I wrote an address tokenizer using machine learning
A few years ago, I was assigned the task to extract the city/suburb names from our crawler results. I wrote a parser, using a bunch of if/else statements and regular expressions. It worked mostly, except in some extreme cases. In order to parse those extreme cases, I added more if statements and more obscure regular expressions. At the end I feel the code was very unreadable.
But was I an incompetent programmer? A few months ago I read a blog post about using machine learning to do address parsing, and I realized my old approach of creating rules, is not how our brains work. A lot of cases really requires us thinking in terms of possibility (“if there are more than three characters followed by this, it is probably a street”). These are fuzzy logics, but my if/ else regular expressions are discrete logics operating on a boolean level.
So as a pet project, I decided to implement an address parser in Ruby. In the Python community they already have Parserator. So why not in Rubyland? I am from Taiwan, so I also want to try applying that to addresses here.
I used the Conditional Random Fields model, though reading the Wikipedia article fried my brain:
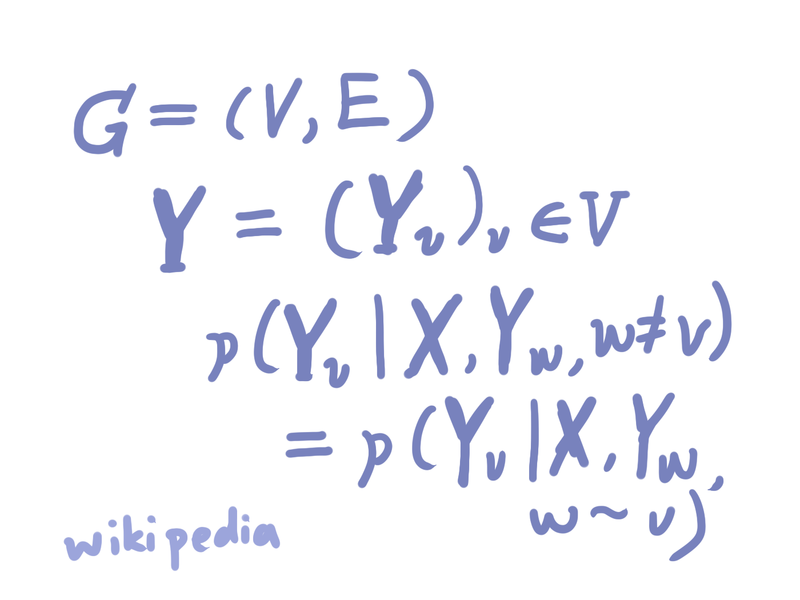
I don’t understand any of these. However I still keep my hopes that I can just copy & paste something and it would work out eventually. Though we don’t know how to create a lego block, we can still build things using it without all the background knowledge right?
The first step is to gather the training data. My friend said that these are confidential, and can cost money. So I looked elsewhere. Eventually I found out that there are people adding address entries on this site called OpenStreetMap. Regional data can be downloaded at this site called Gisgraphy. The file is in .pbf, which stands for Protocolbuffer Binary Format. So I used pbf_parser gem to access the data inside. Not all data are for addresses, some are bus routes and some are geometry data. I wrote a parser to extract addresses into the a SQL database. There were around 15000 records.
Though in OSM people enters address in different sections such as city and suburb, in reality it is not strictly followed as to which field represents what. This is especially true in Eastern countries. there are a few distinct levels which does not have an English counterpart. People also puts the full address in the street field and the like. So I have to write scripts to boldly move the data around the columns, add new columns to match Taiwanese address rules. I feel I have touched more than 2/3 of the addresses. I call this part cleaning.
Once cleaning is done, all we have to do is to feed those data in to train the model. Sylvester Keil wrote two Rubygems to do CRF training, one of which is called wapiti. It is a wrapper to a C library of the same name. He was very kind and helped me when I wanted to know how to use the gem.
Eventually I was able to feed my data into wapiti and create a model file. Some East-Asian languages have the property that pharaes are not separated by space characters, I have to chop the address into individual characters, and then feed them in. On the other end, when the model determines the result, I then have to combine neighbouring characters of the same label back into a phrase.
The result was much better than I expected, it can parse common addresses just fine. All of these are me writing no rules at all. I created a website for people to try out http://addresstokenizer.lulalala.com/, so I can also gather some new data.
People do inform me extreme cases where the tokenization fails. As my first time writing something using Machine Learning, the feeling is quite different, as something like this:
if result.wrong?
say "Not me! It's its fault!
The machine is too stupid to learn~~"
shrug
guilt = 0 # do not feel guilty at all~
else
say "Hehe"
feels "complimented"
happiness += 100
end
I provided a gem (https://github.com/lulalala/lulalala_address_tokenizer) and provided a model file. The gem is intended for East Asian addresses (Chinese, Japanese and Korean), so if you are in these region, please try create your own model. Once you plug it in, it should just work. Once I have time, I plan to put my training data online for others to make correction on.