Rails 6.1's ActiveModel Errors Revamp
The Rails 6.1 will probably be released this year, and with it comes the major changes in ActiveModel Errors. I want to explain the rationale behind the change, and how we can prepare for the upgrade.
Wrap each error as an object
When our model object contains invalid data, the valid? call would fill up the errors information. Historically this behaved like a hash which maps attribute to error messages. Later in Rails 5.0, a separate details hash was added for accessing additional information.
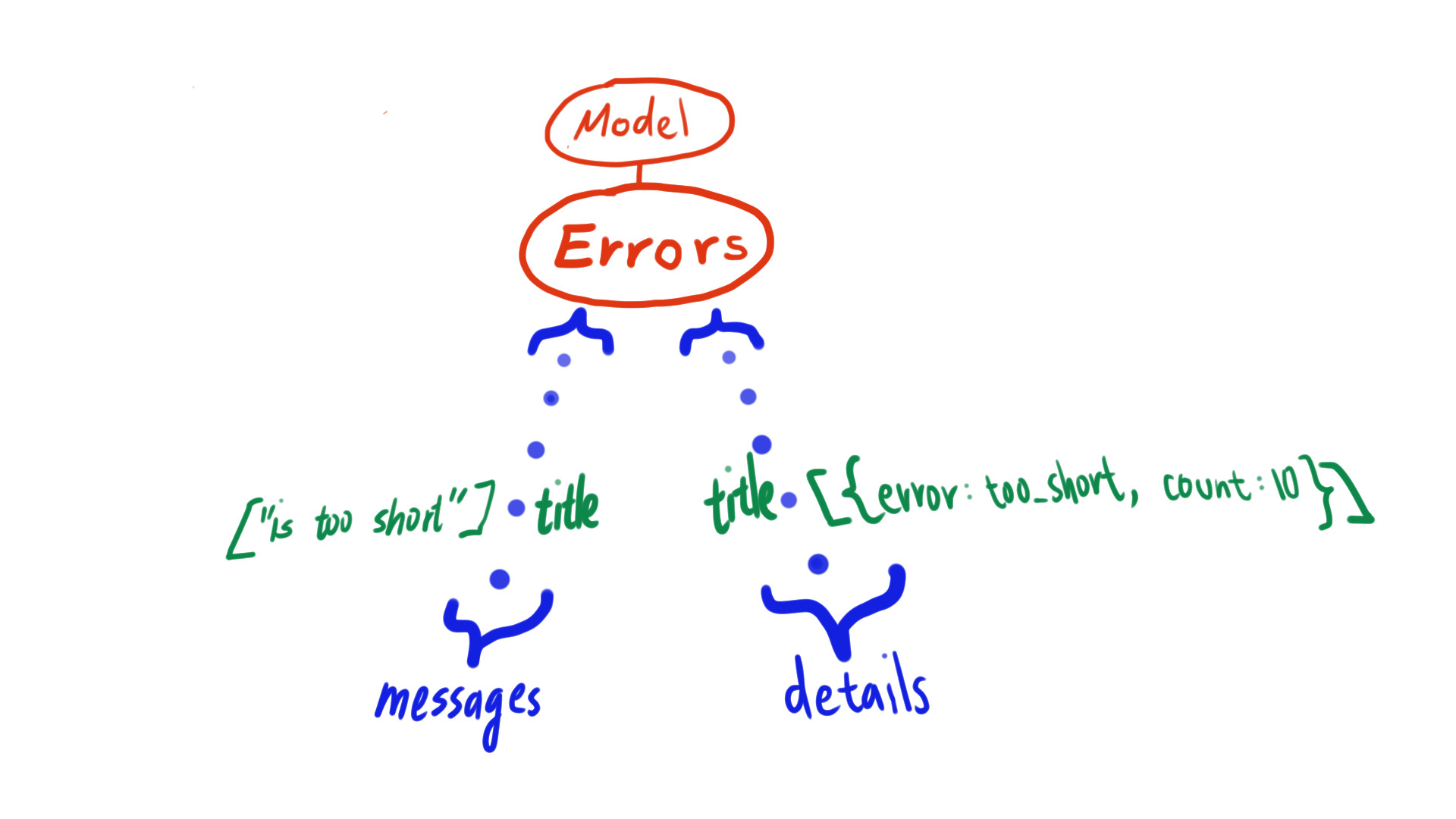
The two hashes are supposed to be a one-to-one mapping, but finding one message’s corresponding details is actually a chore. You need to get the index of the message, then use that to access the second hash. The two hashes can also get out of sync in a few edge cases. Keeping internal state consistent is more difficult than one would imagine,
For this reason, in 6.1, we wrapped the relevant error information together as an Error object. Now under the hood of book.errors is an array of Error objects.
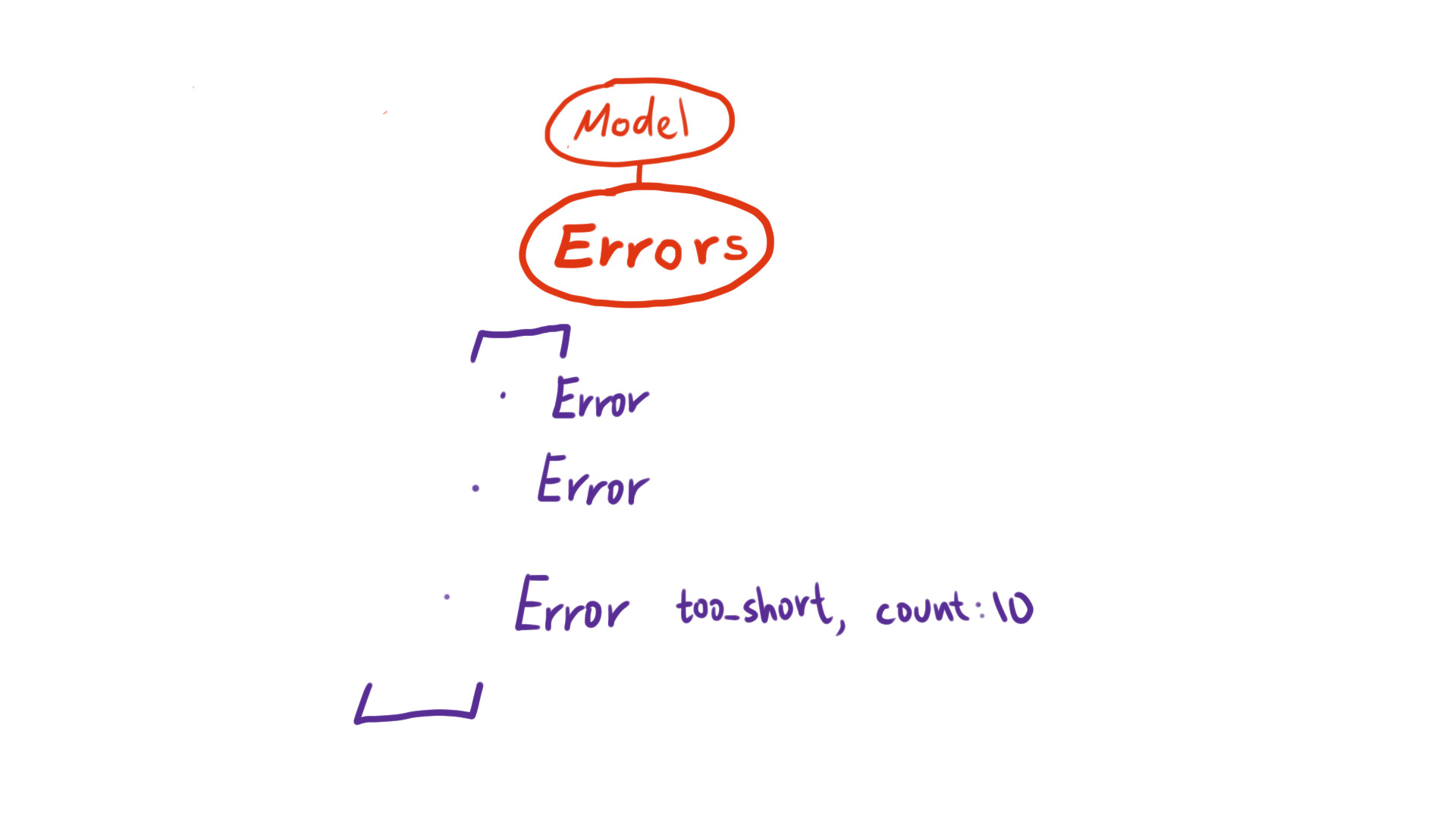
As with all big changes, there will be deprecations and breaking changes which requires updates. I will list the most important things below:
How to upgrade?
Message and details
Instead of accessing messages, full_messages and details, which covers all errors, each individual Error object knows about its own information:
e = ActiveModel::Error.new(model, :title, :too_long, count: 1000)
e.message # 'is too long (maximum is 1000 characters)'
e.full_message # 'Title is too long (maximum is 1000 characters)'
e.detail # { count: 1000, error: :too_long }
Enumeration methods
Previously, errors behaves like a hash and we do this:
book.errors.each do |attribute, error_message|
puts attribute
puts error_message
end
For compatibility, this would result in deprecation message Rails 6.1. What you can do is to use the single arity enumerator:
book.errors.each do |error|
puts error.attribute
puts error.message
end
As shown above, if the block takes only one parameter, it would return the Error objects directly. So when you call first, those would also return the Error object.
Avoid modifying the hashes directly
In the past you can add new errors by appending messages directly on to the hash:
book.errors[:title] << 'is not interesting enough.'
book.errors[:title].clear
This would now also raise a deprecation warning, because it is no longer the source of truth, but generated from the Error objects when called. Instead always use the add interface, or enumeration methods:
book.errors.add(:title, 'is not interesting enough.')
book.errors.delete_all { |error| error.type == :too_long }
Manipulating the following will have no effect:
errorsitself as a hash (e.g.errors[:foo] = 'bar')- the hash returned by
errors#messages(e.g.errors.messages[:foo] = 'bar') - the hash returned by
errors#details(e.g.errors.details[:foo].clear)
Removal of hash-like interface
As we move towards the array like data representation, several hash-like interfaces will be deprecated and removed. These include:
errors#slice!errors#valueserrors#keys
Misc
errors#to_xmlwill be removed.errors#to_hwill be removed, and can be replaced witherrors#to_hash.
New things
To help filtering the errors, a new where method is provided. Its method signature is different to ActiveRecord query method though. You can filter by:
- attribute name (required)
- error type (optional)
- options (optional)
Only supplied params will be matched.
book.errors.where(:name) # => all errors related to name attribute.
book.errors.where(:name, :too_short) # => all name attribute errors of being too short
book.errors.where(:name, :too_short, minimum: 2) # => all name attribute errors of being too short and minimum being 2
The new import method (which merge! uses) allows errors to be nested. This is especially helpful for association validation or ActiveInteraction, where deep nesting can occur. Nested error opens up possibility to access more information in such cases.
delete method now accepts more granular filters, so you can delete specific type of error within an attribute.
There are also one additional benefit: now we have a dedicated class for this, it will be easier to monkey patch, and for gem authors to write new extensions.
Conclusion
If you are interseted, you can check out the original pull request. You can also read the official doc for more information.
As the code is still changing constantly, and me forgetting things here and there, there are probably some errors in this post. I’ll keep this updated, but apology in advance.
If you have some suggestion please feel free to leave a comment below or open an issue on Rails repository. Thanks!